Google Gemini Vision for Computer Vision Workflows
Multimodal AI models are changing how we build, debug, and improve computer vision datasets. Google's Gemini Vision models, spanning from Nano to Pro, combine powerful visual understanding with natural language, unlocking workflows that were previously manual, slow, or impossible.
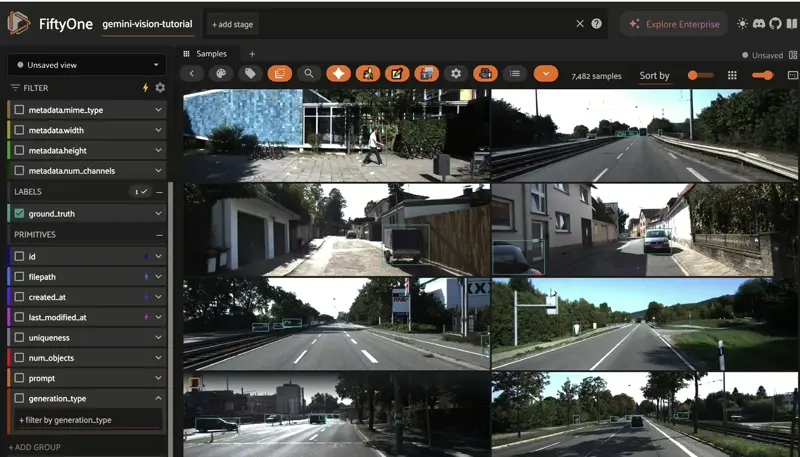
In this post, I'll walk through how Gemini Vision can be applied to real-world computer vision tasks: understanding images through natural language, extracting structured data with OCR, generating synthetic training data, editing images for augmentation, and analyzing video content. All from a practical, data-centric perspective.
What is Google Gemini Vision?
Google Gemini is a family of multimodal AI models developed by Google DeepMind. The Vision capabilities extend across model sizes, including Nano, Flash, and Pro, each offering different tradeoffs between speed and capability:
- Multimodal Understanding: Process images and text together for deep contextual analysis
- 1M Token Context Window: Analyze large visual and textual data in a single request (Gemini 3.0)
- Image Generation: Create new images from text descriptions
- Image Editing: Modify existing images with natural language instructions
- Video Understanding: Analyze temporal sequences with event detection and timestamping
- Adjustable Reasoning: Control analysis depth with configurable thinking levels
These capabilities, when integrated into a data-centric workflow, let you go from exploring a dataset to improving it without leaving your analysis environment.
Visual Q&A: Asking Questions About Your Data
The simplest and often most powerful starting point is asking natural language questions about your images:
- What objects appear most frequently?
- Are there anomalies or unusual samples?
- What is happening in this scene?
This is especially useful when working with large or unfamiliar datasets. Instead of manually browsing thousands of images, you can query them conversationally.
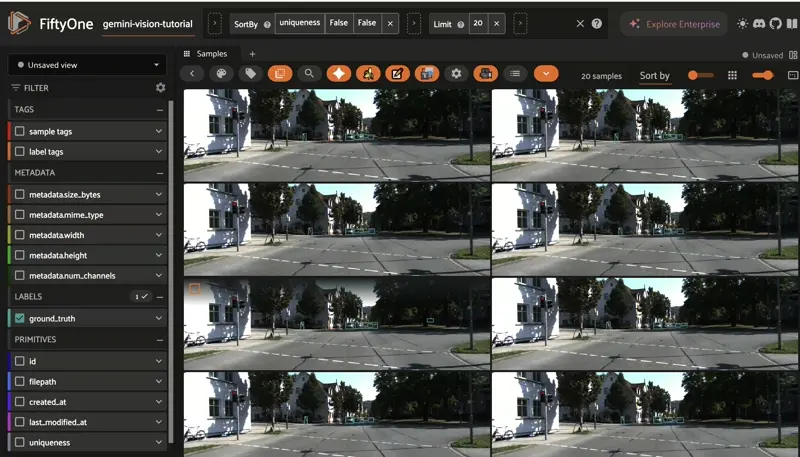
For example, with an autonomous driving dataset like KITTI (7,481+ annotated images), you can quickly assess scene diversity, identify edge cases, and validate assumptions before training.
OCR: Extracting Structured Information from Images
Gemini Vision can dynamically extract structured information from documents such as invoices, receipts, and forms, then map it back as annotations with bounding boxes.
This enables workflows like:
- Auditing document datasets at scale
- Validating OCR annotations against ground truth
- Building analytics pipelines from unstructured visual data
In the example above, a receipts dataset is enriched with extracted fields (invoice numbers, dates, totals, vendor names), making unstructured documents searchable and filterable.
Spatial Understanding: Beyond Object Recognition
Gemini Vision doesn't just recognize what is in an image. It also understands where things are and how they relate spatially. This is critical for robotics, autonomous driving, and any task requiring fine-grained spatial reasoning.
Using datasets like ALOHA (robot manipulation demonstrations), Gemini can point to specific components, highlight regions of interest, and visualize spatial relationships between objects, all through natural language queries.
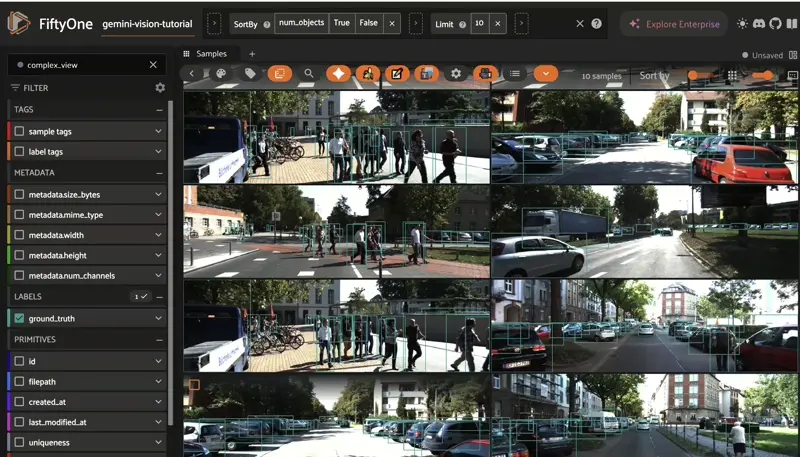
Dataset Quality Analysis: Finding What's Missing
Before reaching for generative AI, it's essential to understand your dataset's characteristics. A typical analysis workflow includes:
Class Distribution
With the KITTI dataset, the class imbalance is immediately visible:
Object Class Distribution
==========================
Car: 28,742
DontCare: 11,295
Pedestrian: 4,487
Van: 2,914
Cyclist: 1,627
Truck: 1,094
Misc: 973
Tram: 511
Person_sitting: 222
Cars dominate. Trams and sitting people are severely underrepresented.
Uniqueness and Duplicates
Computing uniqueness scores helps identify redundant samples that inflate metrics and waste training time:
Embedding Visualization
UMAP projections of CLIP embeddings reveal clustering patterns. Isolated samples or sparse regions indicate underrepresented scenarios:
Identifying Missing Annotations with Gemini
Here's where Gemini Vision shines: you can ask it to list all objects visible in an image and compare against existing annotations to find gaps.
You can also use Gemini to classify images by scenario characteristics:
- Weather: Clear, rainy, foggy, snowy, cloudy
- Time of day: Dawn, day, dusk, night
- Scene type: Highway, urban, residential, rural
This systematic classification reveals which scenarios your dataset lacks, which is critical information for building robust models.
Generating Synthetic Data for Missing Scenarios
Once gaps are identified, Gemini's text-to-image generation can fill them. Example prompts for autonomous driving:
prompts = {
"fire_hydrant": "A city street with a fire hydrant in the foreground, dashboard camera",
"motorcycle": "A motorcyclist on a highway during sunset, car perspective",
"cyclist_rain": "A residential street with a cyclist, rainy weather, dashcam view",
"night_traffic": "A busy urban intersection at night with traffic lights and pedestrians",
"foggy_highway": "A foggy morning highway with trucks and cars, limited visibility"
}
Each generated image includes metadata tracking the prompt and generation method, which is essential for traceability in production pipelines.
Image Editing for Data Augmentation
Beyond generating new images, Gemini can edit existing ones with natural language:
- "Change the weather to rainy, add rain and wet roads"
- "Make it nighttime with street lights illuminated"
- "Add fog to reduce visibility"
This creates weather and lighting variations from real images. It is a powerful augmentation strategy that preserves scene structure while diversifying conditions.
Scaling the Pipeline
For production workflows, you can batch-process multiple edit prompts across your dataset:
prompts = ["Add rain", "Make it night time", "Add fog"]
async def run_pipeline():
for sample in dataset.limit(num_examples):
for prompt in prompts:
result = await execute_operator(
"image_editing",
params={
"prompt": prompt,
"model": "gemini-3-pro-image-preview",
"use_original_size": True,
},
)
Each generated image is stored with metadata (generation_type, prompt, source_file) for filtering and traceability.
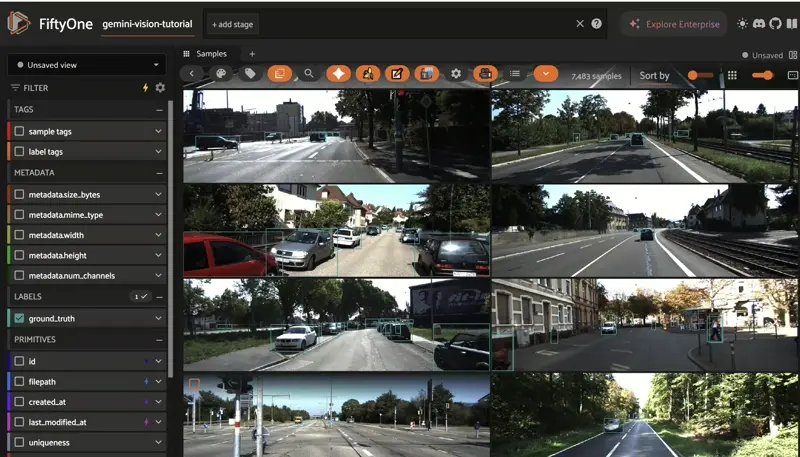
Multi-Image Composition: Style Transfer Across Scenes
Gemini can combine multiple images to transfer styles. For example, applying nighttime lighting from one image to a daytime scene from another. This creates diverse training conditions without leaving the real-image domain:
Video Understanding: Temporal Analysis
Gemini Vision extends to video, enabling temporal analysis that single-frame models can't provide:
- Describe: Detailed video content summaries
- Segment: Temporal segmentation by traffic density, weather, scene type
- Extract: Object timestamps and event detection
- Question: Natural language queries about sequences
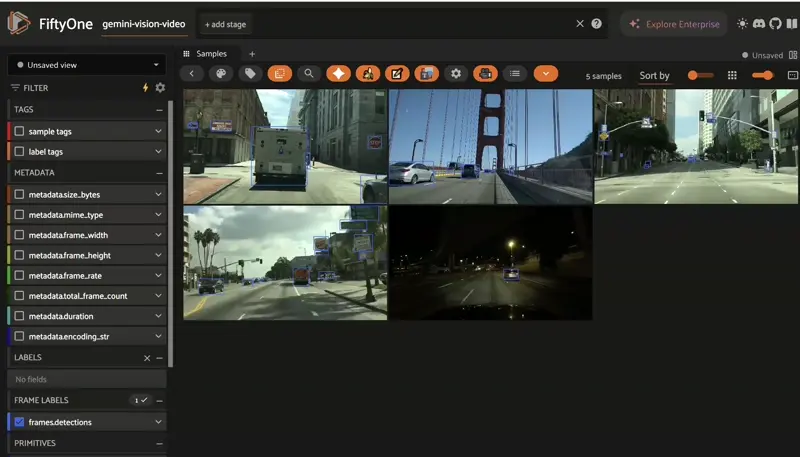
For autonomous driving, this means detecting lane changes, verifying traffic signal compliance, identifying pedestrian interactions, and tracking weather changes, all through natural language queries against video data.
Key Takeaways
By combining Gemini Vision's multimodal reasoning with data-centric computer vision workflows, you can:
- Explore datasets faster: Visual Q&A replaces manual browsing
- Find what's missing: Gemini identifies annotation gaps and scenario blind spots
- Fill the gaps: Text-to-image generation creates targeted synthetic data
- Augment intelligently: Image editing creates realistic variations preserving scene structure
- Analyze video: Temporal understanding unlocks insights hidden in single frames
The Gemini model family (Nano for edge, Flash for speed, Pro for maximum capability) means these workflows scale from real-time inference on devices to batch processing in the cloud.
Try It Yourself
For the complete hands-on walkthrough with code, datasets, and interactive visualization, check out the full tutorial:
- Google Gemini Vision in FiftyOne: Full Tutorial
- Gemini Vision Plugin
- Google Gemini API Documentation
- KITTI Dataset
About the author: Adonai Vera is a Google Developer Expert for AI & ML, focused on computer vision workflows and multimodal AI applications.